Working with Data: Python and the Pandas Library

Introduction
One purpose of Data Science is to identify the patterns and structure of data, making it interpretable and easy to work with, but how can we achieve this great purpose? In this article, I would like to show you how to work with Python and Panda’s library to clean and structure your data.
With Pandas library, we perform a lot of data operations, like importing CSV files, creating data frames and data preparation. To install pandas, you need to have Python installed on your machine, all you need to do is open your Python terminal and type pip install pandas.
let’s create sample data store it in a variable ‘users’ and add some missing values.
import pandas as pd
import numpy as np
users= {
'first-name': ['Sadeeq', 'Umar', 'Sani', 'Ibrahim', np.nan, None, 'NA'],
'last-name': ['Usaman', 'Isah', 'Abdullahi', 'Kabeer', np.nan, np.nan, 'Missing'],
'email': ['saus@gmail.com', 'uisah@yahoo.com', 'sani10@gmail.com', None, np.nan, 'mtechymou@gmail.com', 'NA'],
'age': ['33', '55', '63', '36', None, None, 'Missing']
}convert it into a pandas Data Frame
df = pd.DataFrame(users)
df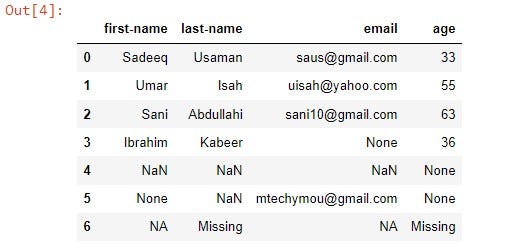
from the above output, row four contains NaN values we can drop the using dropna() fuction.
df.dropna(axis='index', how='any')
Here, ‘index’ is for rows, and ‘any’ means match any cell.
Changing how to ‘all’ returns all rows that have at least one cell without NaN (in row 4, every cell was NaN):
You can set the axis to ‘columns’ to filter by columns:
Use ‘subset’ to filter based on specific columns (rows 3 and 4 contain ‘NaN’ or ‘None’ in the email column):
df.dropna(axis='index', how='all', subset=['email'])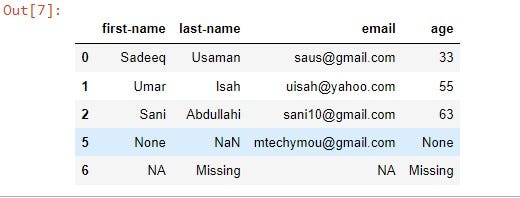
Replace custom missing values with proper NaN (np.nan) values:
df = pd.DataFrame(users)
df.replace('NA', np.nan, inplace=True)
df.replace('Missing', np.nan, inplace=True)
df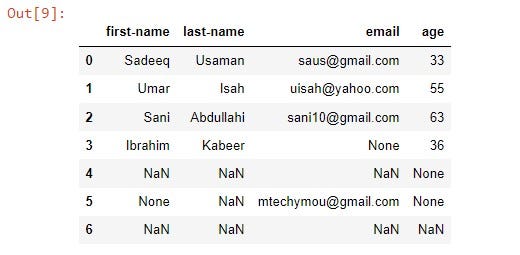
let’s use dropna() funtion again
df.dropna()
Now you can see the above output looks clean.
Show every cell that has a NaN type value:
df.isna()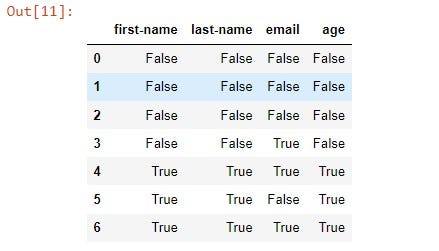
you can use df.fillna() to replace NaN values with a custom value:
Casting DataTypes
df.dtypes
output:
first-name object
last-name object
email object
age p object
dtype:objectObject datatype is often text, never numeric. The values in the age column are text, not numbers! Won’t be able to calculate the mean of those values. i.e. df['age'].mean() will raise TypeError: can only concatenate str (not “int”) to str.
df['age'] = df['age'].astype(float)
print(df['age'].mean())
df.dtypes
output:
46.75
first object
last object
email object
age float64
dtype: object
Conclusion
By now, we’ve seen how powerful pandas are for analysis and data manipulation.


Comments